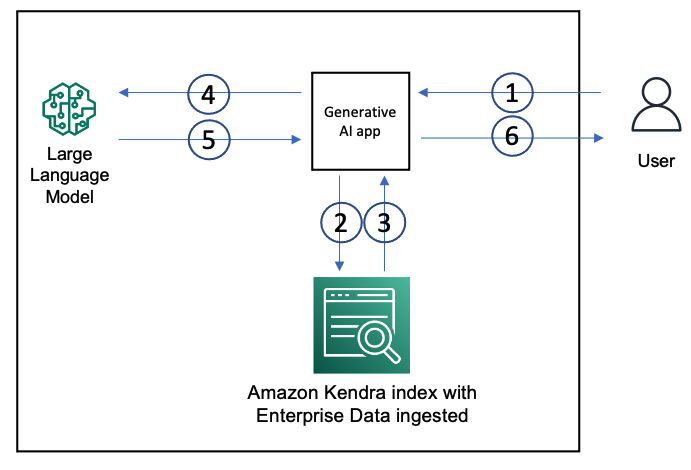
昨天我們介紹了AWS Bedrock Knowledge Bases和Azrue AI Search,這些都有提供將文件轉乘向量的功能,但是其實也有不轉成向量,單純用非結構文件的方式進行關鍵字搜尋的服務,也能和LangChain串接。
https://aws.amazon.com/tw/kendra/
透過連接器,可以是AWS的或是其他第三方的資料源整合進Kendra內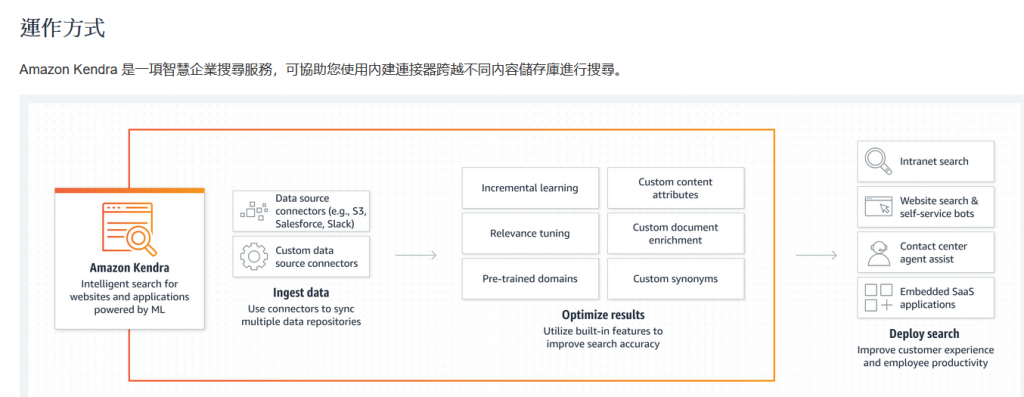
連接器的種類https://aws.amazon.com/tw/kendra/connectors/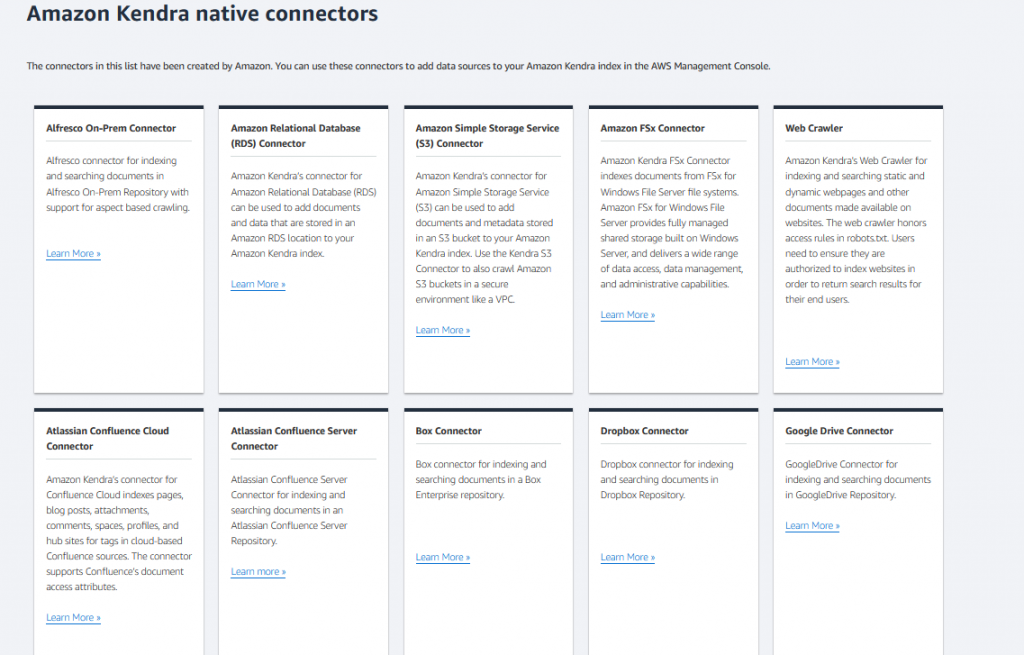
在LangChain的串接上,只需要提供ID即可
https://python.langchain.com/v0.2/docs/integrations/retrievers/amazon_kendra_retriever/
rom langchain_community.retrievers import AmazonKendraRetriever
retriever = AmazonKendraRetriever(index_id="")
其實我在查看文件時,很容易看見這兩個名子,目前推測這兩個名子可能是同個服務?
https://cloud.google.com/products/agent-builder?hl=zh-cn
在使用上我們會針對資料儲存庫和應用程式去進行使用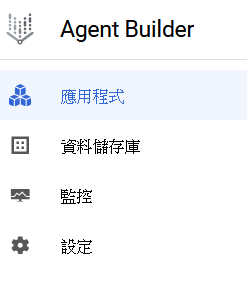
資料來源的種類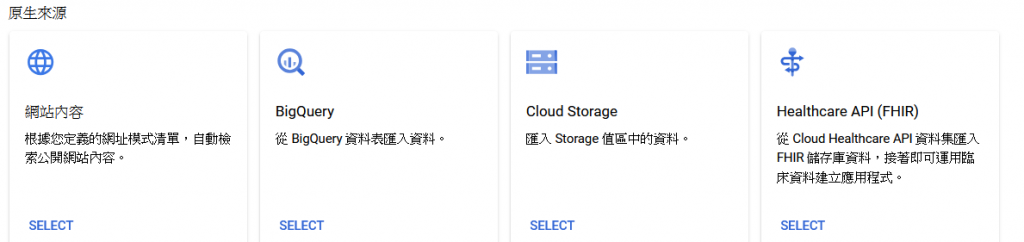
langChain串接上,主要說明SEARCH_ENGINE_ID、DATA_STORE_ID
from langchain_google_community import (
VertexAIMultiTurnSearchRetriever,
VertexAISearchRetriever,
)
PROJECT_ID = "<YOUR PROJECT ID>" # Set to your Project ID
LOCATION_ID = "<YOUR LOCATION>" # Set to your data store location
SEARCH_ENGINE_ID = "<YOUR SEARCH APP ID>" # Set to your search app ID
DATA_STORE_ID = "<YOUR DATA STORE ID>" # Set to your data store ID
retriever = VertexAISearchRetriever(
project_id=PROJECT_ID,
location_id=LOCATION_ID,
data_store_id=DATA_STORE_ID,
max_documents=3,
)
明天我們會針對AgentBuilder進行說明,上傳我們的文件上去,作為RAG資料來源